Part 1
AI-Assisted EDA
15 min

Part 1
15 min
Part 2
20 min
Part 3
15 min
10 min
Vendor-hosted (Google, OpenAI, Anthropic…)
Self-hosted (Llama, GPT-oss, Qwen…)
Cloud for most work, local for sensitive data
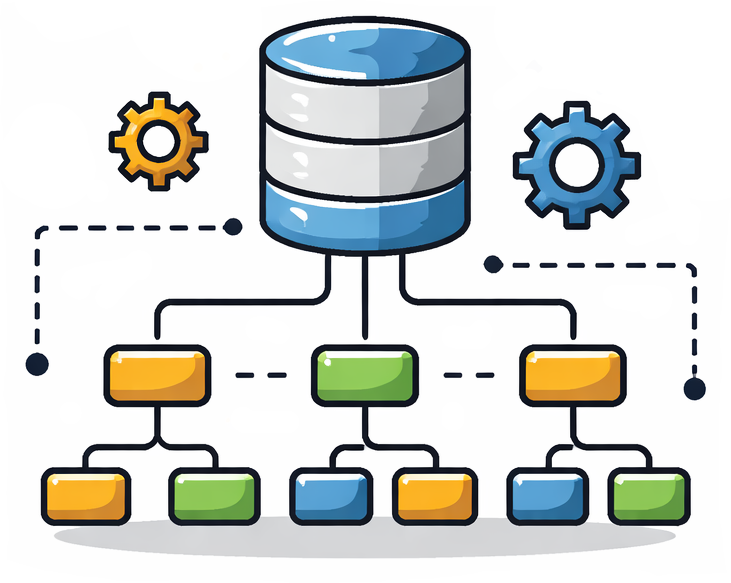
AI models come and go, but the way an institution organizes, governs, and shares its data determines whether any of them are useful.
| Domain | Tables |
|---|---|
| Reference | Organization, AllowedValues, BudgetCategory |
| Core | Personnel, ContactDetails, Project |
| Pre-Award | RFA, RFARequirement, Proposal, ProposalBudget |
| Post-Award | Award, Modification, Terms, Subaward, CostShare, and more |
| Financial | Fund, Account, FinanceCode, Transaction, IndirectRate, Invoice |
| Personnel & Effort | ProjectRole, Effort |
| Compliance | ComplianceRequirement, ConflictOfInterest |
| Operations | ApplicationSystem, ServiceRequest |
| Faculty Dev | ProjectCohort, CohortParticipation |
| System | Document, ActivityLog |

xkcd.com/927 — CC BY-NC 2.5
The hardest part of adopting a shared schema is the translation work. AI changes that equation. It can read a source schema and the UDM, then propose the mapping automatically.
Who changed what, when, and why?
Schemas enforced, anomalies detected, freshness monitored.
Failover, backup, point-in-time recovery.
Storage and compute scale independently.
Open formats, interchangeable engines, no lock-in.
Structured, semi-structured, and unstructured in one platform.
A small team can operate it without dedicated platform engineers.
No redundant copies, compute scales to actual workload.
Raw data, exactly as received. No transformation.
Per-source mapping to UDM schema. One view per source per table.
Unified UDM tables. UNION ALL across Silver, deduped by primary key.
App-specific views. Joins, aggregations, access control.
Store everything. Retain raw files, soft deletes, and metadata. The audit trail starts here.
Translate once per source. AI or human maps each column to the UDM. No business logic, only standardization.
One truth. If two sources provide the same entity, priority rules pick the winner. Auto-generated by the platform.
Purpose-built. Each app gets exactly the view it needs. Dashboards, AI agents, and APIs all read from here.
Tracing VERAS AGENCY_TYPE from source to application.